
1. Agent 架构范式
参考:LLM Powered Autonomous Agents. Lilian Weng, OpenAI.
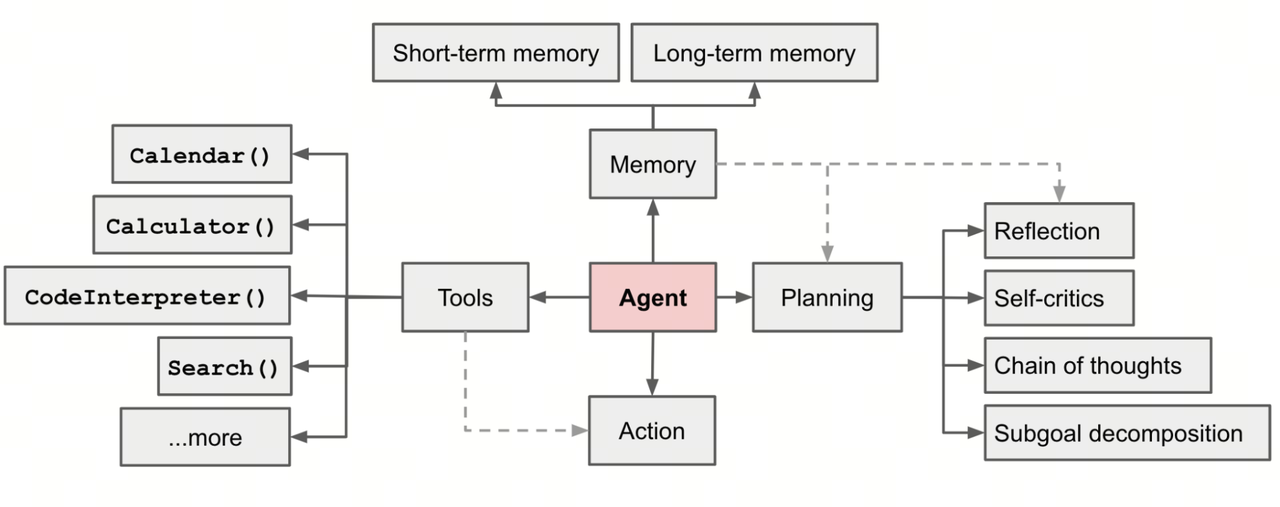
1.1 规划(Planning)
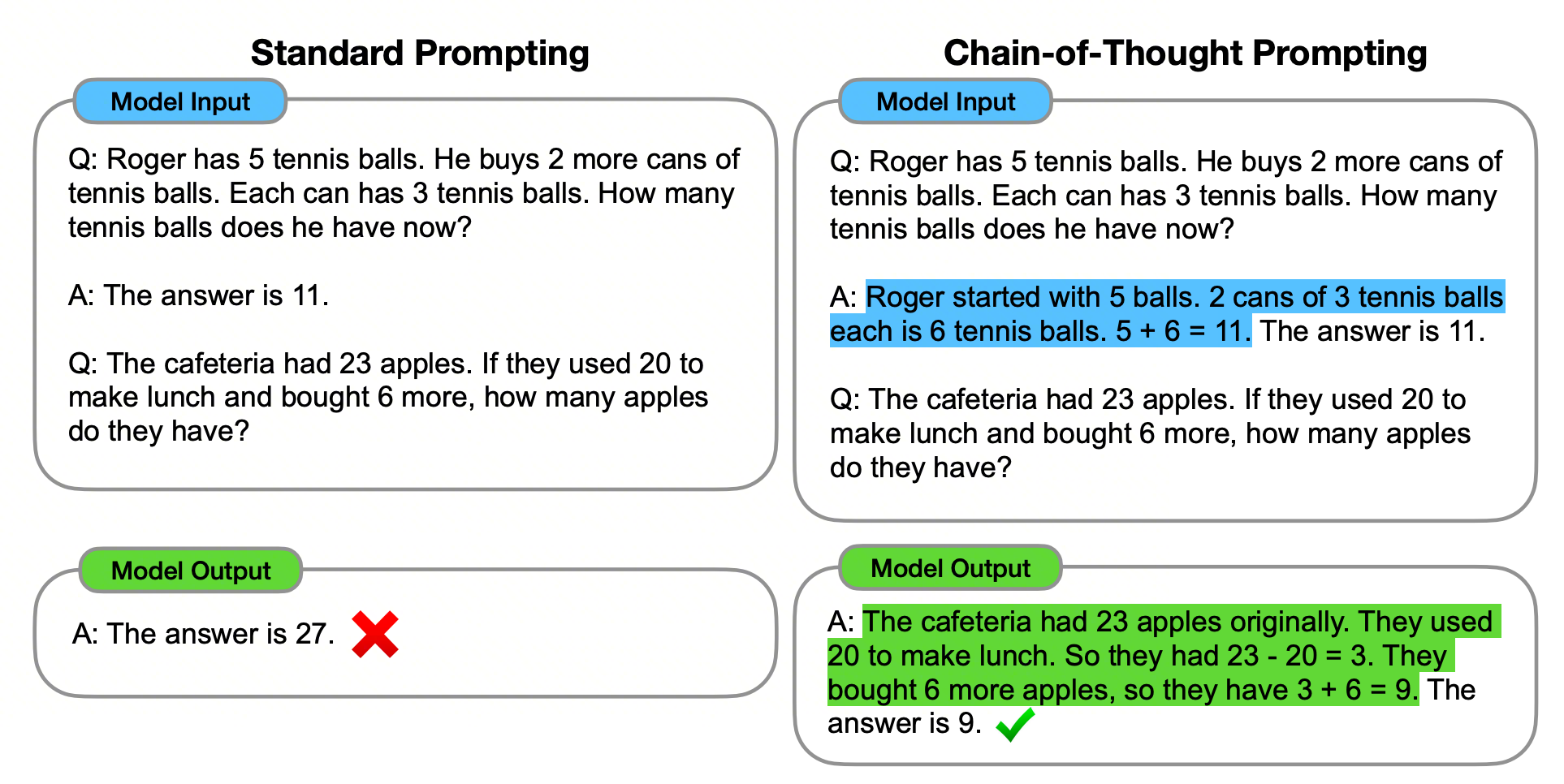
1.1.1 Chain-of-Thought
参考:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Wei et al. 2022.
CoT 是一种提示工程(Prompt Engineering)技术,它模拟了人类解决问题时“一步一步来”的线性思考过程,引导 LLM 在给出最终答案前,显式地生成一系列中间推理步骤的方法。
- 将一个复杂问题分解为连续的、逻辑关联的子问题并依次求解,显著提升了模型在算术、常识和符号推理任务上的表现。
- 将模型的“黑箱”决策过程部分“白箱化”,使得推理路径变得可见、可审查。
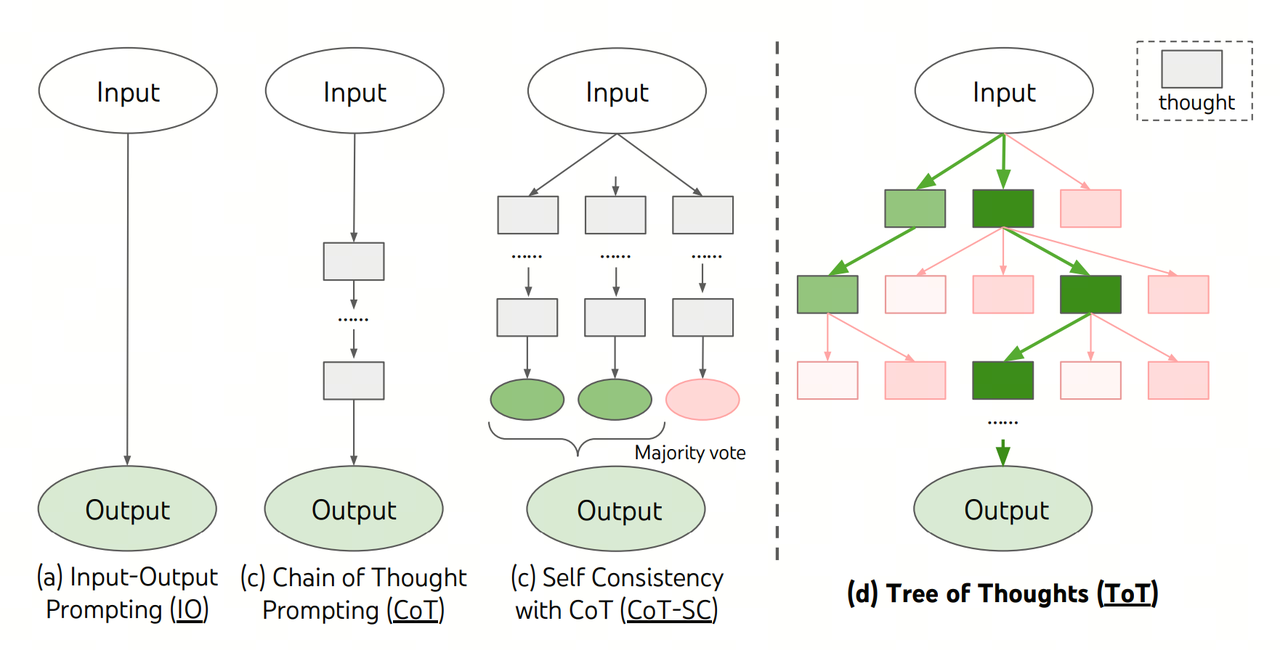
Extension: Tree of Thoughts(ToT)
参考:Tree of Thoughts: Deliberate Problem Solving with Large Language Models. Yao et al. 2023.
ToT 是对 CoT 的扩展,它将推理过程组织成一棵树状结构。在每个节点上,模型会生成多个不同的“想法”(thoughts),并对这些想法进行评估。通过广度优先或深度优先搜索,ToT 能够探索多个推理路径,并在必要时进行回溯,从而在需要复杂规划或探索性解决问题的任务上表现更优。然而,ToT 的计算成本较高,是其在生产环境中应用的主要障碍。
1.1.2 ReAct
参考:ReAct: Synergizing Reasoning and Acting in Language Models. Yao et al. 2023.
ReAct 范式将推理(Reasoning)与行动(Acting)紧密结合,形成一个“思考-行动-观察”的循环。Agent 不再是一次性生成所有推理步骤,而是在每个时间步交替进行:
- 思考(Thought):基于当前状态和历史,LLM 进行推理,决定下一步要采取的行动(通常是调用某个工具)。
- 行动(Action):执行该行动,例如调用一个搜索引擎 API。
- 观察(Observation):获取行动返回的结果,例如 API 的输出。这个循环不断重复,直到任务完成。ReAct 使 Agent 能够与外部环境(如 API、数据库)进行动态交互,并根据反馈调整其计划。
ReAct 极大地增强了 AI Agent 解决现实世界问题的能力,是当前最主流和实用的 Agent 范式。

1.2 记忆(Memory)

- 感觉记忆(Sensory Memory)
- 人类记忆特征:记忆的最早阶段,可在原始感官刺激结束后保留其印象(如视觉、听觉信息),通常持续几秒钟,包含图像记忆(视觉)、声像记忆(听觉)和触觉记忆(触觉)等子类别。
- LLM Agent 类比:为原始输入(包括文本、图像或其他模态)学习嵌入表示(Embedding Representations)的过程。
- 短期记忆(Short-Term Memory, STM)或工作记忆(Working Memory)
- 人类记忆特征:存储当前意识到且用于执行复杂认知任务(如学习和推理)的信息,容量约为 7 个项目(由 Miller 1956 年提出),持续 20 - 30 秒。
- LLM Agent 类比:类似于上下文学习(In-context Learning),短暂且有限,受限于 Transformer 有限的上下文窗口长度。
- 长期记忆(Long-Term Memory, LTM)
- 人类记忆特征:能将信息存储极长时间,从几天到数十年不等,存储容量基本无限,包含外显 / 陈述性记忆和内隐 / 程序性记忆两种子类型。
- 外显 / 陈述性记忆(Explicit / Declarative Memory):关于事实和事件的记忆,可有意识回忆,包括情景记忆(事件和经历)和语义记忆(事实和概念)。
- 内隐 / 程序性记忆(Implicit / Procedural Memory):无意识的记忆,涉及能自动执行的技能和惯例,例如骑自行车或在键盘上打字。
- LLM Agent 类比:可视为 Agent 在查询时可访问的外部知识库,通过快速检索实现访问。
1.2.1 RAG
检索增强生成(Retrieval-Augmented Generation, RAG)通过引入外部知识库,有效缓解了大型语言模型(LLM)的幻觉问题和知识时效性瓶颈,成为构建知识密集型应用的事实标准。然而,一个基础的、被称为 Naive RAG 的架构,即遵循“索引 - 检索 - 生成”三步流程的简单实现,在生产环境中很快会遇到性能天花板。其核心痛点源于流程的刚性与信息处理的浅层次。
RAG 核心痛点
- 召回质量不稳定:用户的查询往往是多样的、模糊的,甚至是错误的。Naive RAG 直接使用原始查询进行向量检索,难以应对复杂的问句意图,导致召回的文档片段(Chunks)与问题不匹配或相关性低。
- 上下文污染与噪声:即使召回的文档包含答案,固定大小的文本块(Chunking)策略也常常引入大量无关信息。这些噪声会污染 LLM 的上下文窗口,分散模型注意力,甚至误导其生成错误的答案。
- 长文依赖与上下文碎片化:对于需要理解整篇文档或跨多个章节才能回答的复杂问题,简单的 Chunk 检索无法构建完整的上下文图景。LLM 得到的只是零散的片段,无法进行有效的推理和总结。
为了突破这些局限,业界探索出了一系列高级 RAG(Advanced RAG)技术,其核心思想是为检索流程引入更多的“智能”与“深度”,从简单的“问 - 查 - 答”模式向“理解 - 规划 - 迭代 - 生成”的动态流程演进。
检索前(Pre-retrieval)优化
- 查询重写(Query Rewriting):不直接使用用户输入,而是先让 LLM “反思”查询。例如,将其分解为多个子问题(如 LlamaIndex 的
SubQuestionQueryEngine),或根据对话历史生成更具体的独立查询。 - 查询扩展(Query Expansion):同样利用 LLM,为一个模糊的查询生成多个不同角度的变体,或补充相关的同义词、术语,然后并行检索,增加召回多样性。
检索中(Retrieval)优化
- 混合检索(Hybrid Search):结合关键词检索(如 BM25)和向量检索的优势。前者保证了对特定术语的精确匹配,后者则覆盖了语义相似性,两者结合能显著提升召回的鲁棒性。
- 多路检索(Multi-Path Retrieval):同时使用向量检索、关键词检索、混合检索、图检索等多种检索方法,合并结果。
- 层次化索引与多向量索引:不再将所有 Chunks 一视同仁。例如,可以先对文档进行摘要,检索时先匹配摘要,定位到相关文档后再在文档内部进行细粒度检索。多向量索引则为同一 Chunk 生成多个不同维度的向量(如一个关注字面,一个关注语义),以应对不同的查询类型。
检索后(Post-retrieval)优化
- 重排序(Re-ranking):这是提升 RAG 性能最有效的手段之一。在初步召回(例如
Top-K=20)的文档后,使用一个更强大的交叉编码器(Cross-encoder)模型(如BGE-Reranker-large)对“查询 - 文档”对进行打分,重新排序,筛选出最相关的Top-N(例如N=3)个文档送给 LLM。 - 上下文压缩与管理:即使是重排后的文档,也可能存在冗余信息。通过
LLMLingua或Recomp等技术,在不损失关键信息的前提下,对上下文进行压缩,使其更精简、更符合 LLM 的“注意力胃口”。
1.3 工具(Tools)
1.3.1 Function Calling / Tool Calling
参考:Function calling - OpenAI Developers.
Function Calling vs. Tool Calling:两者在当前语境下基本可以互换使用。Function Calling 是 2023 年 6 月首次推出时的名称。后来,为了涵盖更多类型的外部能力(如内置的 code_interpreter、file_search 等),OpenAI 将其统一到更宽泛的 Tool Calling(工具调用)框架下。在 API 层面,表现为 functions 参数被更通用的 tools 参数取代。
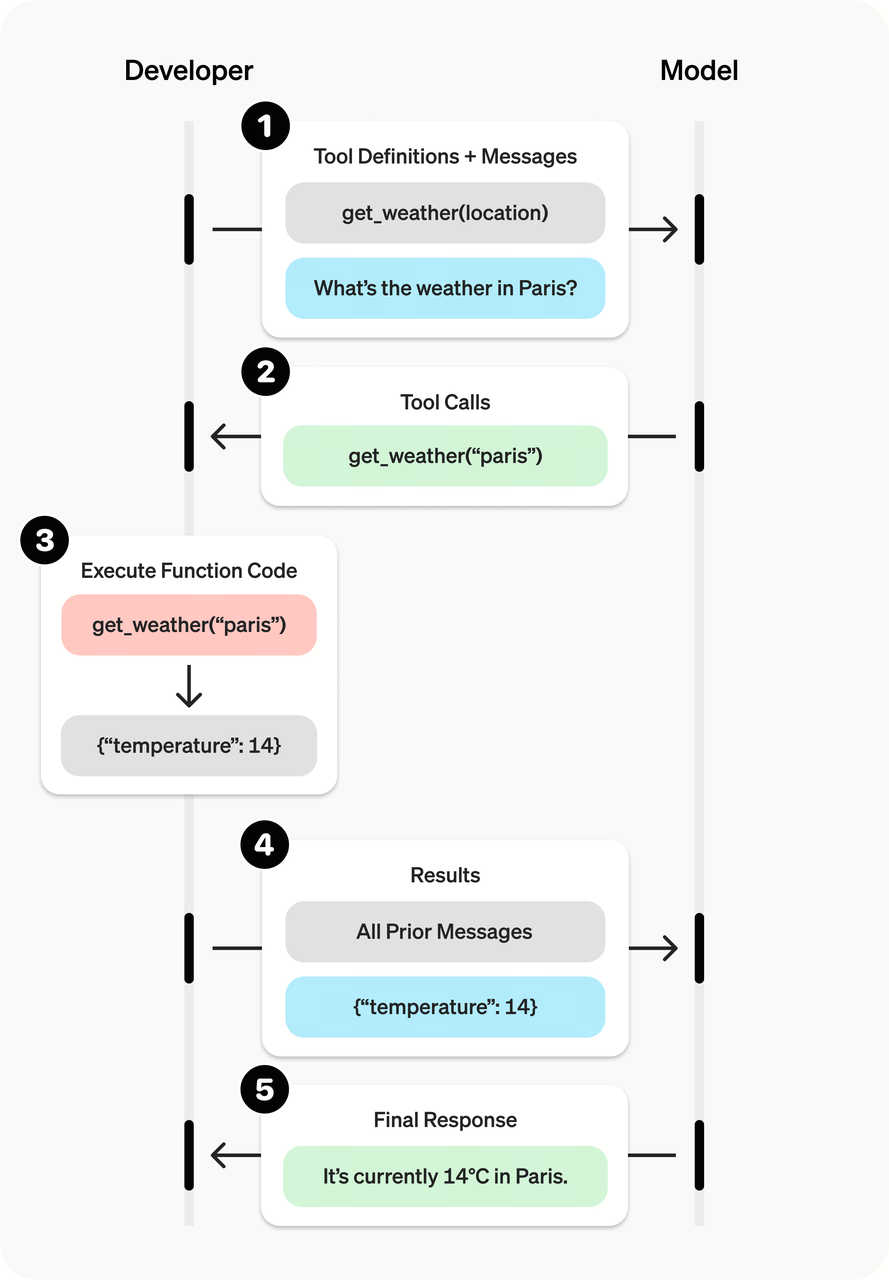
Function Calling 的本质是一个“三步走”的协同工作流,关键在于模型本身从不执行任何代码。它的职责是“意图识别”与“参数生成”。
- 开发者定义工具(Define):在向模型发起请求时,开发者通过
tools参数提供一个或多个工具的 JSON Schema 定义。这份定义就像一份“工具使用说明书”,告诉模型每个工具的名称(name)、功能描述(description)以及需要哪些参数(parameters)。 - 模型生成调用指令(Generate):模型在理解用户输入(Prompt)后,判断是否需要以及如何使用这些工具来完成任务。如果需要,模型的返回结果中会包含一个或多个
tool_calls对象,其中清晰地指明了要调用的函数名称和根据用户意图解析出的、符合 Schema 规范的参数 JSON。此时,API 的finish_reason通常为tool_calls。 - 开发者执行并返回结果(Execute & Return):开发者的应用程序接收到
tool_calls后,根据其中的信息在自己的环境中执行相应的函数(如调用一个真实的 API、查询数据库或执行本地代码)。然后,将函数的执行结果封装成一个role为tool的新消息,连同之前的对话历史再次发送给模型。 - 模型总结并最终回应(Summarize):模型接收到工具执行结果后,会结合原始问题和工具返回的信息,生成一段自然的语言回复给最终用户。
模型负责“思考”和“规划”,而实际的“行动”则由外部代码完成。
1.3.2 MCP(Model Context Protocol)
参考:Introducing the Model Context Protocol. Anthropic.
MCP,全称为模型上下文协议(Model Context Protocol),是一种开放的、标准化的通信协议,旨在解决大型语言模型(LLM)应用与外部世界(如工具、数据库、API、文件系统等)交互的难题。
可以将其类比为 USB-C 接口。在 USB-C 出现之前,每种设备(鼠标、键盘、显示器)都有自己独特的接口,导致连接和兼容性问题频发。而 USB-C 通过统一标准,让任何遵循该规范的设备都能“即插即用”。同样,MCP 也致力于成为 AI 领域的“通用接口”,让任何支持 MCP 的 AI 应用都能无缝连接并调用任何支持 MCP 的工具或数据源(服务端),从而极大地降低集成成本,促进 AI 生态繁荣。
核心角色
- MCP Host(宿主):通常指用户直接交互的 AI 应用程序,例如桌面 AI 助手(如 Claude Desktop)、AI 驱动的集成开发环境(IDE,如 Cursor)或任何集成了 LLM 的应用。Host 是整个交互的发起方,负责管理用户界面、编排任务流程,并最终向用户呈现结果。
- MCP Client(客户端):这是 MCP 的独特之处。它并非一个独立的程序,而是内嵌于 Host 应用中的一个组件。每个 MCP Server 都会在 Host 中对应一个专门的 MCP Client 实例。它负责将 Host 中 LLM 生成的工具调用意图,转换为标准化的 MCP 协议消息,并管理与特定 Server 之间的专用连接。
- MCP Server(服务端):一个独立的、轻量级的程序,是具体能力的提供方。它可以封装对本地文件系统、数据库、企业内部 API 甚至复杂工作流的访问。Server 遵循 MCP 协议,向 Client 暴露其所能提供的能力(如 Tools、Resources、Prompts),并执行 Client 发来的调用请求。
如果缺少 Client(Host 直连 Server)
- 高度耦合:Host 需要为每个 Server 单独处理协议版本、能力发现、认证和状态管理,代码逻辑会变得异常复杂和臃肿。
- 扩展性差:每增加一个新的 Server 或一种新的传输方式,都需要修改 Host 的核心代码,维护成本极高。
- 安全性低:缺乏统一的隔离层,不同 Server 之间的状态和权限容易混淆,安全风险增大。
一次完整的 MCP 交互生命周期
- 初始化(Initialize):Host 中的 Client 首次与 Server 建立连接时,会发送
initialize请求。双方在此阶段进行“握手”,协商协议版本、交换彼此支持的能力(如 Server 是否支持工具、Client 是否支持用户输入elicitation等)。 - 能力发现(Discovery):初始化成功后,Client 会向 Server 发送
tools/list、resources/list等请求,以发现 Server 究竟提供了哪些可用的工具和资源。Server 返回详细的能力清单,包括每个工具的名称、描述和输入参数规范。 - 工具调用(Tool Call):当用户向 Host 发出指令,且 LLM 判断需要使用外部工具时,它会生成一个符合函数调用(Function Calling)规范的意图。Host 内的 Client 捕捉到这个意图,并将其构造成一个标准的
tools/call请求(包含工具名称和参数),发送给对应的 Server。 - 执行与返回:Server 接收到请求后,执行相应的内部逻辑(如查询数据库、调用 API),并将执行结果封装成
tools/call的响应,返回给 Client。 - 结果注入与响应生成:Client 将结果递交给 Host,Host 再将其注入到 LLM 的上下文中。LLM 基于新的信息(工具执行结果)生成最终的自然语言答复,呈现给用户。
- 通知(Notification):在整个生命周期中,Server 可以随时向 Client 发送异步通知,例如
tools/list_changed,告知其能力列表发生了变化(如新增或删除了一个工具),Client 收到后可以重新进行能力发现,以保持信息同步。
1.3.3 Agent Skills
参考:Equipping agents for the real world with Agent Skills. Anthropic.
Skills 是 Anthropic 为其 AI Agent(尤其是 Claude Code)赋予领域专业知识和执行复杂现实世界任务能力的一套组合式、可扩展且可移植的机制。其核心理念在于,与其为每个场景构建碎片化、定制化的 Agent,不如通过一种标准化的方式,将人类的程序性知识(Procedural Knowledge)打包成可复用的“技能”,让通用 Agent 能够动态加载和使用,从而“专精”于特定任务。
Agent Skill 的所有能力都构建在一个以目录为基础的结构之上。每个技能被封装在一个独立的目录中,所有相关的定义、指令和资源都内聚于此。信息的组织与披露严格遵循“元数据 → 指令 → 辅助资源”的三层结构,每一层都服务于不同的目的,并在任务执行的不同阶段被动态加载。
Skills 的运行逻辑紧密围绕“模型推理”与“工具调用”的循环,其精髓在于渐进式披露和动态加载:
- 启动与发现:Agent 启动时,扫描指定的技能目录(如
~/.claude/skills),读取所有SKILL.md文件头部的name和description,并将其整合进 System Prompt。此时,模型仅知道“有哪些技能”以及“它们大致能做什么”。 - 任务触发与技能选择:当用户提出一个任务时(如“请帮我填写这份 PDF 申请表”),模型在其上下文中看到了用户的请求以及所有可用技能的简短描述。基于对任务的理解,模型判断出“PDF Skill”是完成此任务最相关的能力。
- 技能加载:模型决策调用文件系统工具,读取
pdf-skill/SKILL.md的内容到上下文中。现在,模型获得了操作 PDF 的详细指令。 - 深度加载与工具执行:
SKILL.md的指令可能会引导模型执行更复杂的操作。例如,指令提示“如果要填写表单,请阅读forms.md文件获取详细步骤,并运行extract_fields.py脚本来识别所有可填写的表单域”。模型随即会:- 读取
forms.md,获取更具体的指令。 - 调用代码执行工具,运行
extract_fields.py脚本。
- 读取
- 循环与完成:脚本的执行结果会返回给模型,模型根据这些结果(如表单域列表)和
forms.md中的指令,继续与用户交互或直接生成填写后的内容,直至任务完成。
1.3.4 总结
Function Calling、MCP 和 Agent Skills 三者并非相互替代,而是在一个分层架构中扮演着互补的角色,共同构成一个强大而灵活的 Agent 系统。我们可以用一个比喻来阐释三者之间的关系:
- Function Calling 是“神经信号”:它是由大脑(模型)产生的一个精确、结构化的指令,指明了“要做什么”以及“用什么参数做”。
- MCP 是连接大脑与肌肉的“神经束”:它负责将“神经信号”(Function Calling 请求)快速、标准地传递到指定的“肌肉纤维”(MCP Server 上的工具),并将肌肉的反馈(比如调用一个 API、查询数据库或运行一段代码的执行结果)传回大脑。MCP 通过标准协议抹平了各种“肌肉”(工具)的接口差异和治理边界,确保整个系统协调高效。
- Skills 是大脑中存储的“技能包”:它封装了为了完成一个复杂目标(如“投篮”),大脑该如何组合一系列“神经信号”(Function Calling),并通过特定的“神经通路”(MCP)去激活一系列“肌肉”(工具)的完整逻辑、顺序和策略。一个“投篮”的技能包,不仅包含调用“伸手”“屈膝”“跳跃”等肌肉动作的序列,还包含何时调用、如何协调,以及在不同情况下(如有人防守时)如何调整的策略。
2. OpenClaw
OpenClaw 是一个以 Agent 形态呈现的框架。它提供了完整的 Agent 运行时环境,同时开放了所有扩展接口,让用户既能直接使用,也能深度定制。
2.1 Architecture
与许多追求复杂规划与推理链条的学术性 AI Agent 不同,OpenClaw 的设计哲学回归到了一个更务实、更具工程美感的核心:事件驱动(Event-Driven)。其本质可以被理解为一个本地部署的、以消息为中心的个人 AI 运行时(Personal AI Runtime)。它像一个操作系统内核,为大型语言模型(LLM)这颗“大脑”连接了“五官”和“四肢”,使其能够感知并行动。
网关(Gateway):系统的神经中枢
网关是 OpenClaw 架构的绝对核心,它是一个基于 Node.js 的常驻后台服务。它的职责并非思考,而是作为所有信息流动的“交通枢纽”与“控制平面”:
- 消息路由:接收来自各种通信渠道(如 Slack、Discord、飞书、WhatsApp 等)的用户消息,并将其转发给对应的 Agent 实例。
- 事件分发:将不同来源的输入统一封装成“事件”,推入系统的事件循环中,等待处理。
- 状态管理:维持与各个渠道的连接状态、用户会话(Session)以及 Agent 的在线状态(Presence)。
意图分析与任务编排引擎(Agent / Workflow Engine)
当消息进入网关后,核心的编排引擎开始工作。它首先借助 LLM 分析用户的自然语言指令,识别其真实意图。例如,当用户说“帮我看看今天下午还有空吗”,引擎需要理解这是在查询日历,而不是简单的聊天。
识别意图后,引擎会进一步进行任务规划,将一个复杂的请求拆解成一系列可执行的步骤。这个过程类似于一个项目经理制定行动计划,决定需要调用哪些工具、以何种顺序执行。
事件驱动的输入系统:让 Agent “活”起来
OpenClaw 之所以感觉“主动”和“鲜活”,关键在于其多样化的事件输入源,它们共同构成了 Agent 的感知系统。所有输入最终都会被转化为统一的事件格式,由事件循环(Event Loop)进行处理。
| 输入类型 | 描述与应用场景 |
|---|---|
| 消息(Messages) | 最主要的输入来源。用户通过绑定的聊天工具直接与 Agent 对话,下达指令、获取反馈。这是 OpenClaw 实现“对话式控制”的基础。 |
| 心跳(Heartbeats) | 周期性的定时器事件。例如,可以配置一个每 30 分钟触发一次的 Heartbeat,让 Agent 定期检查新邮件、刷新新闻摘要或监控系统状态,赋予 Agent 持续的“生命感”。 |
| 计划任务(Crons) | 基于 Cron 表达式的精确调度任务。这使得 Agent 能够执行严格定时的自动化流程,例如“每周一早上 9 点生成周报”“每天下午 5 点提醒我整理日历”。 |
| 钩子(Hooks) | 源于系统内部状态变化的触发器。例如,当一个 Agent 启动或完成一项技能时,可以触发一个 Hook,用于日志记录、状态更新或链式触发其他任务。 |
| Webhooks | 来自外部系统的 HTTP 回调。这是 OpenClaw 与第三方服务(如 GitHub、IFTTT、企业内部系统)集成的关键。例如,当 GitHub 仓库有新的 Issue 时,通过 Webhook 通知 Agent,使其自动分配任务或通知相关人员。 |
记忆与工作区:可读、可控的“数字抽屉”
与许多将记忆存储在复杂数据库或向量索引中的 Agent 不同,OpenClaw 创新地采用了以 Markdown 文件为核心的本地工作区(Workspace)作为其主要的记忆载体。
- 本地持久化:所有的配置、对话历史、用户偏好、长期知识都以
.md文件的形式保存在用户本地的~/.openclaw/workspace目录下。这种设计赋予了用户对 Agent 记忆的完全所有权和透明度。用户可以直接阅读、编辑,甚至通过 Git 进行版本管理。 - 结构化记忆文件:工作区内包含一系列结构化的 Markdown 文件,如
identity.md(Agent 的自我认知)、user.md(对用户的了解)、memory.md(长期知识库),以及按日期存放的每日对话记录。LLM 在处理任务时,会加载这些文件作为上下文,从而实现持久记忆和个性化。
技能(Skills):赋予 Agent “动手”的能力
如果说 LLM 是大脑,那么技能就是 OpenClaw 的“双手”。一个“技能”通常是一个脚本或一段代码,封装了与特定服务(如 Google 日历、Jira)或能力(如文件操作、浏览器自动化)的交互逻辑。OpenClaw 拥有一个庞大的社区驱动的技能库(ClawHub),包含数千种预置技能,用户也可以轻松创建自己的技能来满足特定需求。技能是封装好的、可供 LLM 调用的“工具集”。
技能市场(ClawHub):OpenClaw 社区维护了一个技能市场,用户可以通过简单的命令(如 openclaw skill install <skill-name>)方便地安装和扩展 Agent 的能力,形成了强大的生态系统。
执行器(Executor)
当任务计划制定完成、所需工具也已确定后,执行器便开始行动。它可以:
- 控制本地系统:运行 Shell 命令,读写文件,管理进程。
- 实现浏览器自动化:通过 Chrome DevTools Protocol(CDP)控制浏览器,实现自动填表、数据抓取、网页截图等操作。
- 调用第三方 API:与外部服务(如企业内部系统、公共 API)进行数据交换。
模型与渠道的抽象:开放与中立
OpenClaw 在设计上保持了高度的模型中立性和渠道多样性。
- 多模型支持:它不绑定任何特定的 LLM,通过统一的接口,支持接入 OpenAI GPT 系列、Anthropic Claude 系列、Google Gemini、DeepSeek 以及通过 Ollama 等框架运行的各类本地模型。用户可以根据成本、性能和隐私需求自由切换。
- 多渠道集成:支持超过 20 种主流的即时通讯和团队协作工具,用户可以在自己最熟悉的界面上与 Agent 互动,实现了“AI in your chat”。
以网关和事件循环为中心的架构,使得 OpenClaw 具有极高的可扩展性和灵活性。添加一个新的聊天工具,只需实现一个新的通道模块;增加一项新能力,只需开发一个新的技能。整个系统松耦合、高内聚,展现了出色的工程设计。
2.2 Memory
OpenClaw 记忆系统的基石是一个极其简洁而深刻的理念:文件即真相(Files are the source of truth)。与依赖外部数据库(如向量数据库)作为记忆载体的传统 RAG 架构不同,OpenClaw 将所有记忆,无论是身份认知、长期知识还是每日的对话流水,全部以人类可读、可编辑的 Markdown 文件形式存储在本地工作区(~/.openclaw/workspace/)。
核心优势
- 完全的透明度与可控性:你可以随时使用任何文本编辑器打开这些
.md文件,精确地了解 AI “记住”了什么。如果发现记忆有误,可以直接修改或删除,AI 的“知识库”尽在你的掌控之中。 - 极低的运维成本与零依赖:无需部署和维护复杂的数据库服务,整个记忆系统就是一个本地文件夹。这使得 OpenClaw 极易部署和迁移,甚至可以使用 Git 对 AI 的记忆进行版本控制、分支和回滚。
- 隐私与数据主权:所有敏感信息都存储在本地设备上,彻底杜绝了将私有数据上传至第三方云服务的风险,保证了数据的绝对主权。
OpenClaw 的记忆系统并非一堆无序的文本文件,而是构建了一个类似人类认知模型的三层记忆栈,每一层都有其明确的定位和加载机制。
三层记忆栈
第一层:引导文件层(Bootstrap Layer)
这一层包含了一系列在 Agent 每次启动或每次会话开始时强制加载到上下文中的核心配置文件。它们共同塑造了 Agent 的基础人格、行为准则和身份认知,如同一个人随身携带的身份证、护照和个人笔记本,无论在何种场景下都不会改变。
SOUL.md:定义 Agent 的人格、价值观与行为边界。它决定了 Agent 的语气(是专业严谨还是活泼风趣)、沟通风格和伦理准则,是 Agent 的“灵魂”所在。AGENTS.md:定义 Agent 的核心操作手册(SOP)和行为规则。例如,“在执行任何有风险的操作前必须先获得用户批准”“在回答问题前先搜索记忆库”等高优先级指令都写在这里。USER.md:存储关于用户的基本画像信息,如用户的姓名、职业、技术偏好、沟通习惯等。Agent 通过此文件了解其服务对象。IDENTITY.md:这是 Agent 的自我身份标识。它通常非常简洁,只包含 Agent 的名字、专属 Emoji、角色定位(例如“一只具有猫咪能量的 AI”)等核心身份元素。这个文件好比 Agent 的身份证,让它在任何时候都能清晰地回答“我是谁”。MEMORY.md:这是精炼的长期核心记忆库。与下面将要提到的每日日志不同,MEMORY.md存储的是那些经过提炼、相对稳定且高价值的持久化信息,例如用户的长期偏好(“我更喜欢使用 TypeScript 而不是 Python”)、关键项目决策、重要里程碑事件等。
第二层:每日日志层(Daily Log Layer)
这一层由 memory/ 目录下一系列以日期(YYYY-MM-DD.md)命名的文件组成。它们是 Agent 的“工作日记”,以仅追加(Append-only)的方式,忠实记录着每天的对话流、临时发现和上下文。
- 自动加载策略:为了在保持上下文连续性的同时避免“上下文溢出”,OpenClaw 默认在每次会话开始时,仅自动加载今天和昨天的日志文件。
- 内容定位:每日日志是原始、未经提炼的信息流。Agent 在对话中学习到的临时信息、正在进行的任务状态、即时性的用户反馈等,都会被写入当天的日志文件。
第三层:检索索引层(Retrieval Index Layer)
尽管记忆以 Markdown 文件形式存在,但当文件日积月累,如何高效地从中找到所需信息便成了关键。OpenClaw 为此构建了一个强大的本地检索索引层,它并非记忆的真相来源,而是真相来源(Markdown 文件)的“加速器”。
- 技术实现:该层通常由一个本地 SQLite 数据库实现,利用其
FTS5扩展进行高效的 BM25 关键词搜索,并结合sqlite-vec等扩展或外部本地模型实现向量语义搜索。 - 混合搜索(Hybrid Search):OpenClaw 的
memory_search工具采用的是“关键词 + 语义”的混合搜索策略。系统会同时进行 BM25 和向量搜索,并将两者的得分按一定权重(例如,语义 70%,关键词 30%)加权融合,从而得到最终的相关性排序。这种方式兼顾了意图理解的模糊匹配(向量)和技术术语、ID 等的精确查找(关键词)。 - 增量索引:系统会监听工作区内记忆文件的变化。任何对
.md文件的修改(无论是 AI 写入还是用户手动编辑),都会在短暂的防抖延迟(如 1.5 秒)后触发增量索引,自动将变更内容进行切片、向量化并更新到 SQLite 索引中。
如果说文件是记忆的载体,那么 LLM 就是决定“记什么”和“怎么记”的大脑。OpenClaw 设计了一套精妙的机制,引导 LLM 在合适的时机,将有价值的信息沉淀到记忆文件中。
预压缩内存刷新(Pre-compaction Memory Flush)
这是 OpenClaw 记忆系统中最具创造性的机制之一,是应对上下文窗口限制的“主动防御”策略。
- 触发逻辑:当一个会话的上下文长度接近模型的最大限制时(例如,已使用 Token 数 > 模型上限 - 缓冲 Token),OpenClaw 不会等到 API 报错,而是会自动触发一个对用户不可见的“静默回合”(Silent Turn)。
- 静默提示:在这个隐藏的回合中,系统会向 LLM 发送一条特殊的系统指令,例如:“会话即将压缩,请在压缩发生前,将任何持久化的事实、偏好或决策写入记忆中。”
- LLM 自主决策:收到指令后,LLM 会回顾当前的对话上下文,自主判断哪些信息是“值得长期记住的”,然后调用
memory_write等工具,将这些提炼后的信息写入MEMORY.md或当天的日志文件memory/YYYY-MM-DD.md。 NO_REPLY与无感知:在完成写入操作后,LLM 会回复一个特殊的NO_REPLY标记。这个标记告诉系统不要将此回合的任何内容展示给用户。随后,系统再执行上下文压缩(Compaction)。
整个过程对用户是完全透明的,但它确保了在短期记忆(会话上下文)被压缩或遗忘之前,最有价值的信息已经被主动、智能地转移到了长期记忆(Markdown 文件)中。
写入建议:MEMORY.md vs. 每日日志
LLM 在决策写入时,还需要判断信息应该存放在哪里。OpenClaw 的系统提示(如 AGENTS.md)中通常会包含明确的指导原则:
- 写入
MEMORY.md的内容- 持久化的事实:例如,“项目 Alpha 的数据库选型是 PostgreSQL 15。”
- 用户的长期偏好:例如,“我倾向于简洁直接的沟通风格。”
- 关键决策与结论:例如,“我们决定在下一个版本中放弃对旧版 API 的支持。”
- 自我修正的规则:当 Agent 犯错并被纠正后,它应该将正确的行为准则写入
MEMORY.md,以避免重蹈覆辙。
- 写入
memory/YYYY-MM-DD.md的内容- 日常对话的流水摘要:例如,“上午与用户讨论了 API 路由的命名规范。”
- 进行中的任务状态:例如,“正在分析
main.py文件,目前进度 30%。” - 临时的发现或数据:例如,“用户分享了一个临时的 API-Key 用于调试。”
- 需要稍后回顾的上下文:任何感觉在当天或第二天可能还会用到的信息。
随时间演化的记忆:一个实例演示
想象一下你刚开始使用 OpenClaw,它的记忆文件都是空的。
- 第一天:你告诉 Agent:“我叫李明,是一名 Python 开发者,我更喜欢使用 VS Code。”
- LLM 决策:Agent 判断这是用户的核心信息。
- 写入操作:调用工具将“李明”和“Python 开发者”写入
USER.md,将“偏好编辑器: VS Code”写入MEMORY.md。
- 第二天:你们讨论了一个新项目“Omega”的技术选型,最终决定使用 FastAPI。
- LLM 决策:这是项目的关键决策。
- 写入操作:在
memory/YYYY-MM-DD.md中记录“与用户讨论 Omega 项目技术选型”,并将最终结论“项目 Omega: 采用 FastAPI 框架”写入MEMORY.md。
- 一周后:你发现 Agent 总是给你推荐一些 Java 相关的库,你纠正它:“别再给我推荐 Java 的东西了,我是写 Python 的!”
- LLM 决策:这是一个强烈的负反馈和行为纠正。
- 写入操作:Agent 会在
MEMORY.md中强化记录“用户编程语言: Python(主要)”,并可能在AGENTS.md中增加一条规则:“在推荐技术库时,优先考虑用户的核心语言 Python。”
- 一个月后:当会话过长,触发了预压缩内存刷新。
- LLM 决策:Agent 回顾最近的对话,发现你们刚刚确定了“Omega 项目下周二上线”这个重要时间点。
- 写入操作:在用户无感知的情况下,将“项目 Omega: 计划于下周二上线”这条信息写入当天的日志文件。
通过这个过程,IDENTITY.md(定义我是谁)、MEMORY.md(记录核心事实)和每日日志(追踪日常进展)随着使用不断丰富,Agent 对你的了解也越来越深入,真正实现了从“通用工具”到“专属伙伴”的进化。
2.3 总结
| 核心要素 | 架构范式(理论侧重) | OpenClaw 设计(工程落地) |
|---|---|---|
| LLM(大脑) | 作为核心控制器,负责推理、决策和驱动整个系统,是所有能力的中心。 | 完全继承。同样将 LLM 作为决策核心,但更强调其作为“意图理解者”和“工具调用选择者”的角色,而非全能的规划者。模型中立是其核心优势。 |
| 规划(Planning) | 极其强调。通过复杂的规划技术(如 ReAct、Reflexion、思维树 Tree-of-Thoughts)进行任务分解和自我反思,追求最优路径和端到端解决复杂问题。 | 显著弱化。不内置重量级、统一的 Planner 循环。规划能力更多是隐式地、分散地体现在 LLM 对技能的理解和组合中,或由特定技能(如 self-improving-agent)提供。更依赖事件驱动和用户指令的即时响应。 |
| 记忆(Memory) | 分为短期记忆(上下文窗口)和长期记忆(外部向量数据库)。强调通过复杂的检索、过滤和合成机制(如 RAG)为 LLM 提供相关知识。 | 创新实现。短期记忆同样依赖上下文窗口,但长期记忆通过本地 Markdown 工作区实现。这种设计牺牲了部分检索效率,但换来了极高的透明度、可控性和隐私性。用户可以直接干预“记忆”,使其更像一个“数字花园”而非黑盒数据库。 |
| 工具使用(Tool Use) | Agent 通过学习调用外部 API(如搜索、计算器、代码执行)来扩展能力,克服 LLM 的内在局限性。 | 发扬光大。通过 Skills 和 SKILL.md 规范,将工具使用的理念工程化、生态化。创建了一个标准化的“工具说明书”格式,使得 LLM 能更可靠地理解和使用工具。技能市场进一步加速了能力扩展。 |
| 架构倾向 | 偏向深思熟虑型(Deliberative)和认知型(Cognitive)架构,强调内部建模、多步推理和从经验中学习。 | 偏向反应型(Reactive)架构,并带有深思熟虑的元素。系统首先对事件做出快速响应,复杂的“思考”过程则被封装在具体的技能执行中,而非在系统层面强制执行。 |
1. 关于“规划”的扬弃
Lilian Weng 范式下的 Agent,其灵魂在于一个强大的 Planner。这个 Planner 像一个项目经理,接收一个宏大目标后,会反复进行任务分解、自我反思(“上一步做得对不对?”),甚至多路径探索(思维树),力求自主地、闭环地完成任务。这在理论上非常完美,但在工程实践中却面临巨大挑战:
- 成本高昂:每一次反思和规划都意味着多次 LLM 调用,成本呈指数级增长。
- 行为不可控:复杂的推理链条容易出错,一旦某个环节出现幻觉,整个任务可能偏离轨道,难以调试和纠正。
- 响应缓慢:对于简单任务,过度的规划显得冗长而低效。
OpenClaw 巧妙地回避了构建一个中心化、重量级 Planner 的路径。它选择了更轻、更可控的事件驱动模型。Agent 的行为主要由外部事件(如一条用户消息)触发。所谓的“规划”,被降级并分散到两个层面:
- LLM 的隐式规划:当用户下达指令时,LLM 基于其对可用技能的理解,在“脑中”进行一次简单、一步到位的“规划”,然后直接调用相应技能。
- 技能的显式规划:复杂的、需要多步操作的任务,被封装成一个独立的、有状态的“规划型技能”。例如,一个“旅行规划”技能,它自己内部会进行多轮的搜索、比较和确认,但对于 OpenClaw 的主事件循环来说,它只是调用了一个技能而已。
这种设计哲学是典型的“关注点分离”:系统层面只负责高效、可靠地响应事件,而复杂的业务逻辑则下沉到可独立开发和维护的技能中。
2. 关于“记忆”的创新
传统 Agent 范式通常采用向量数据库作为长期记忆,通过语义相似度搜索为 LLM 提供上下文。这种方式检索效率高,但存在“黑盒”问题:用户不知道 Agent 到底“记住”了什么,也难以直接纠正其错误记忆。
OpenClaw 的 Markdown 工作区是一个很强的工程创新。它将 Agent 的记忆变得像个人笔记一样可读、可写、可管理。这种“白盒”记忆系统带来了多重优势:
- 隐私与数据所有权:所有数据都在用户本地,没有信息被发送到第三方云服务,从根本上解决了隐私担忧。
- 可解释性与可控性:用户可以随时打开
.md文件,查看 Agent 的“内心世界”,甚至可以直接修改user.md来“告诉”Agent 自己的偏好,或者在memory.md中“植入”一段长期知识。 - 易于集成与备份:纯文本文件可以轻松地被其他工具读取,也可以通过 Git 等工具进行版本控制和备份。