Introduction
A graph database, such as NebulaGraph, is a database that specializes in storing vast graph networks and retrieving information from them. It efficiently stores data as vertices (nodes) and edges (relationships) in labeled property graphs. Properties can be attached to both vertices and edges. Each vertex can have one or multiple tags (labels).
Graph databases are well suited for storing most kinds of data models abstracted from reality. Things are connected in almost all fields in the world. Modeling systems like relational databases extract the relationships between entities and squeeze them into table columns alone, with their types and properties stored in other columns or even other tables. This makes data management time-consuming and cost-ineffective.
NebulaGraph, as a typical native graph database, allows you to store the rich relationships as edges with edge types and properties directly attached to them.
Data Model
NebulaGraph data model uses six data structures to store data. They are graph spaces, vertices, edges, tags, edge types and properties.
Graph spaces: Graph spaces are used to isolate data from different teams or programs. Data stored in different graph spaces are securely isolated. Storage replications, privileges, and partitions can be assigned.
Vertices: Vertices are used to store entities.
In NebulaGraph, vertices are identified with vertex identifiers (i.e.
VID). TheVIDmust be unique in the same graph space. VID should be int64, or fixed_string(N).A vertex has zero to multiple tags.
Edges: Edges are used to connect vertices. An edge is a connection or behavior between two vertices.
- There can be multiple edges between two vertices.
- Edges are directed.
->identifies the directions of edges. Edges can be traversed in either direction. - An edge is identified uniquely with
<a source vertex, an edge type, a rank value, and a destination vertex>. Edges have no EID. - An edge must have exactly one edge type.
- The rank value is an immutable user-assigned 64-bit signed integer. It identifies the edges with the same edge type between two vertices. Edges are sorted by their rank values. The edge with the greatest rank value is listed first. The default rank value is zero.
Tags: Tags are used to categorize vertices. Vertices that have the same tag share the same definition of properties.
Edge types: Edge types are used to categorize edges. Edges that have the same edge type share the same definition of properties.
Properties: Properties are key-value pairs. Both vertices and edges are containers for properties.
Path
In graph theory, a path in a graph is a finite or infinite sequence of edges which joins a sequence of vertices. Paths are fundamental concepts of graph theory.
Paths can be categorized into 3 types: walk, trail, and path.
- A
walkis a finite or infinite sequence of edges. Both vertices and edges can be repeatedly visited in graph traversal. - A
trailis a finite sequence of edges. Only vertices can be repeatedly visited in graph traversal.- A
cyclerefers to a closedtrail. Only the terminal vertices can be repeatedly visited. - A
circuitrefers to a closedtrail. Edges cannot be repeatedly visited in graph traversal. Apart from the terminal vertices, other vertices can also be repeatedly visited.
- A
- A
pathis a finite sequence of edges. Neither vertices nor edges can be repeatedly visited in graph traversal.
Architecture
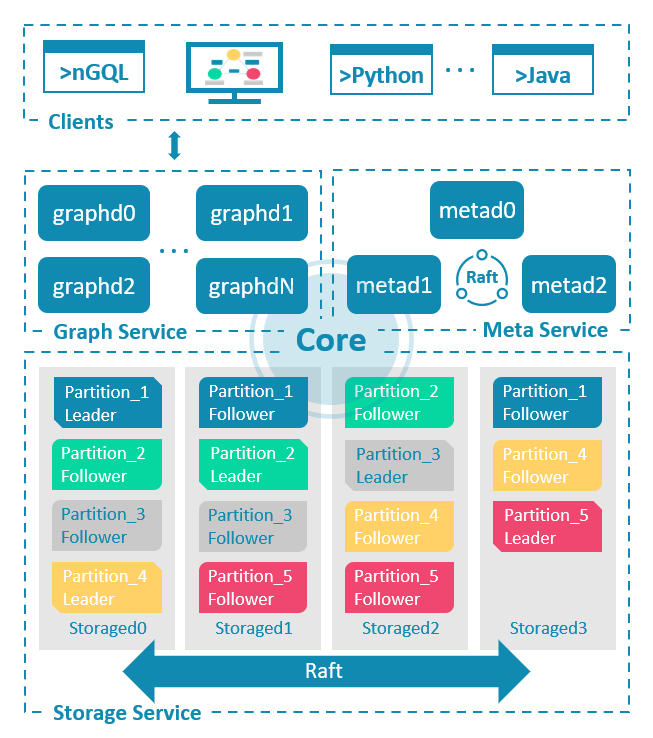
NebulaGraph consists of three services: the Graph Service, the Storage Service, and the Meta Service. It applies the separation of storage and computing architecture.
Meta Service
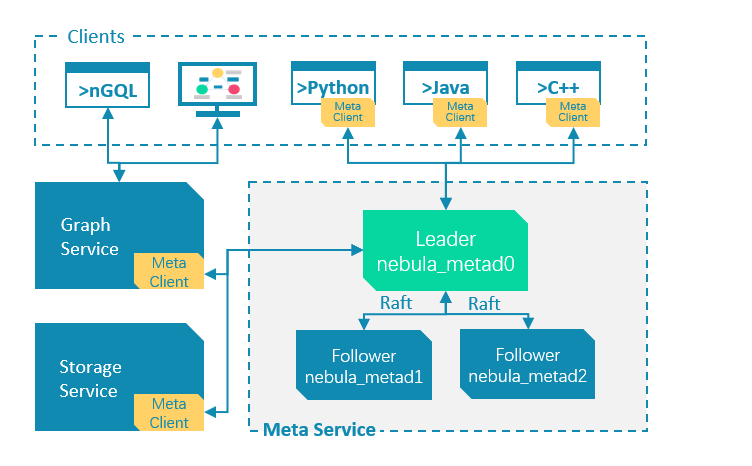
Manages user accounts
Manages graph spaces
Manages partitions
Manages schema information
Manages jobs
The Job Management module in the Meta Service is responsible for the creation, queuing, querying, and deletion of jobs.
Graph Service
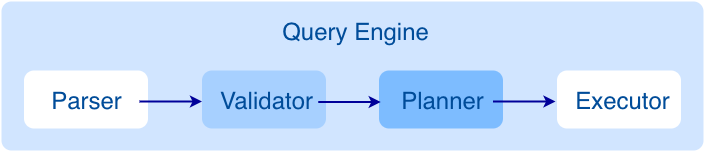
The Graph Service is used to process the query. It has four submodules: Parser, Validator, Planner, and Executor.
After a query is sent to the Graph Service, it will be processed by the following four submodules:
- Parser: Performs lexical analysis and syntax analysis.
- Validator: Validates the statements.
- Planner: Generates and optimizes the execution plans.
- Executor: Executes the plans with operators.
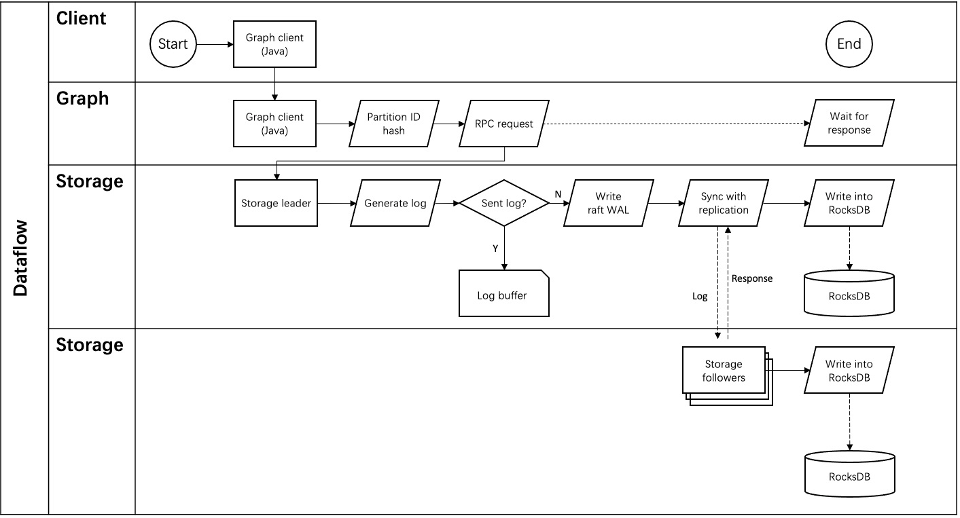
Storage Service
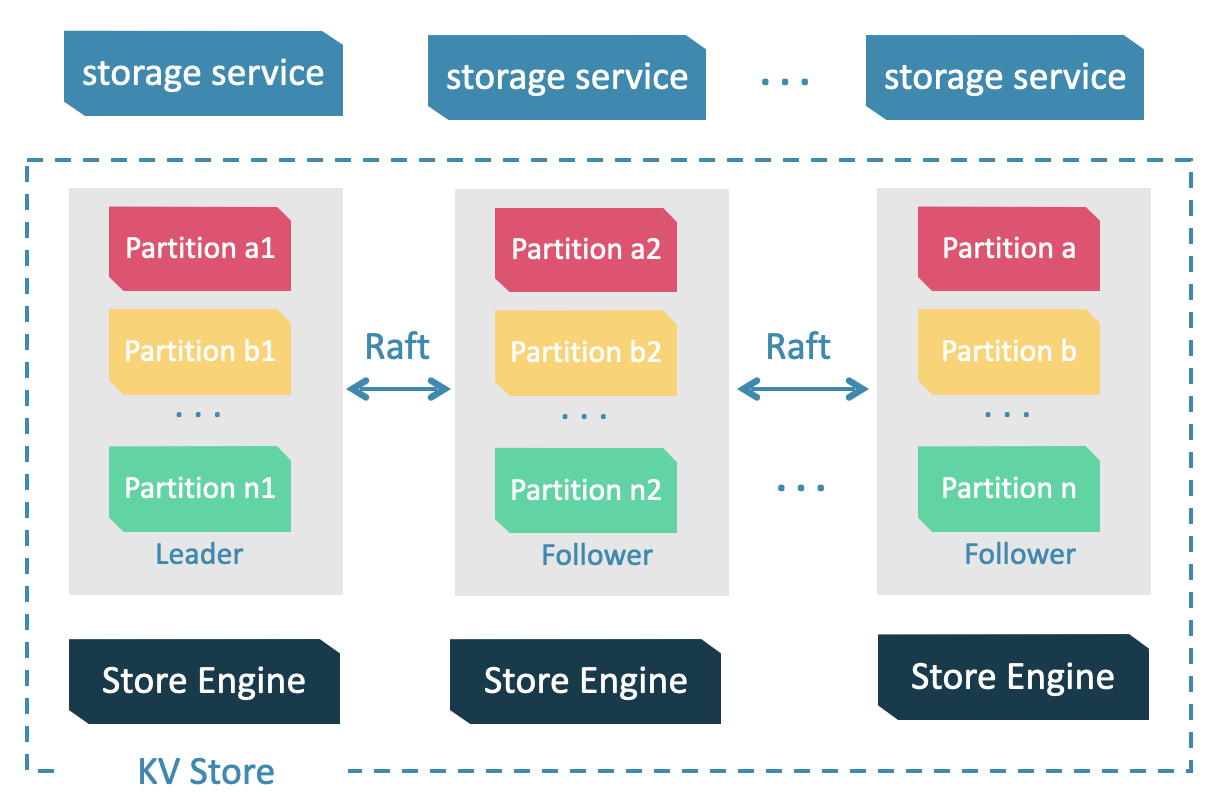
Storage writing
nGQL
Operators
Set
Operator
UNION DISTINCT(or by shortUNION) returns the union of two sets A and B without duplicated elements.Operator
UNION ALLreturns the union of two sets A and B with duplicated elements.
String
| Name | Description |
|---|---|
| + | Concatenates strings. |
| CONTAINS | Performs searchings in strings. |
| (NOT) IN | Checks whether a value is within a set of values. |
| (NOT) STARTS WITH | Performs matchings at the beginning of a string. |
| (NOT) ENDS WITH | Performs matchings at the end of a string. |
| Regular expressions | Perform string matchings using regular expressions. |
List
| List operator | Description |
|---|---|
| + | Concatenates lists. |
| IN | Checks if an element exists in a list. |
| [] | Accesses an element(s) in a list using the index operator. |
Query Statement
The primary query statements in NebulaGraph fall into the following categories:
- FETCH PROP ON : Retrieve properties of a specified vertex or edge.
- LOOKUP ON:Index-based querying of vertex or edge IDs.
- GO:Traverse the graph based on a given vertex and return information about the starting vertex, edges, or target vertices as needed.
- MATCH:Execute complex graph pattern matching queries.
- FIND PATH:Query paths between given starting and target vertices or query properties of vertices and edges along paths.
- GET SUBGRAPH:Extract a portion of the graph that satisfies specific conditions or query properties of vertices and edges in the subgraph.
- SHOW:Obtain metadata information from the database
FETCH PROP ON and LOOKUP ON statements are primarily for basic data queries, GO and MATCH for more intricate queries and graph traversals, FIND PATH and GET SUBGRAPH for path and subgraph queries, and SHOW for retrieving database metadata.
Clause
LIMIT
... | LIMIT [<offset>,] <number_rows>;
SAMPLE
<go_statement> SAMPLE <sample_list>;
WITH
The WITH clause can retrieve the output from a query part, process it, and pass it to the next query part as the input.
WITHhas a similar function with the Pipe symbol in native nGQL, but they work in different ways. DO NOT use pipe symbols in the openCypher syntax or useWITHin native nGQL statements.
UNWIND
UNWIND transform a list into a sequence of rows.
Property Reference
nGQL provides property references to allow you to refer to the properties of the source vertex, the destination vertex, and the edge in the GO statement, and to refer to the output results of the statement in composite queries.
Vertex
| Parameter | Description |
|---|---|
$^ | Used to get the property of the source vertex. |
$$ | Used to get the property of the destination vertex. |
$^.<tag_name>.<prop_name> # Source vertex property reference
$$.<tag_name>.<prop_name> # Destination vertex property reference
Edge
| Parameter | Description |
|---|---|
_src | The source vertex ID of the edge |
_dst | The destination vertex ID of the edge |
_type | The internal encoding of edge types that uses sign to indicate direction. Positive numbers represent forward edges, while negative numbers represent backward edges. |
_rank | The rank value for the edge |
<edge_type>.<prop_name> # User-defined edge property reference
<edge_type>._src|_dst|_type|_rank # Built-in edge property reference
Index
Indexes are built to fast process graph queries. Nebula Graph supports two kinds of indexes: native indexes and full-text indexes.
Indexes can improve query performance but may reduce write performance.
An index is a prerequisite for locating data when executing a
LOOKUPstatement. If there is no index, an error will be reported when executing theLOOKUPstatement.When using an index, NebulaGraph will automatically select the most optimal index.
Indexes with high selectivity, that is, when the ratio of the number of records with unique values in the index column to the total number of records is high (for example, the ratio for
ID numbersis1), can significantly improve query performance. For indexes with low selectivity (such ascountry), query performance might not experience a substantial improvement.
Native Index
Native indexes
Native indexes allow querying data based on a given property. Features are as follows.
There are two kinds of native indexes: tag index and edge type index.
Native indexes must be updated manually. You can use the
REBUILD INDEXstatement to update native indexes.Native indexes support indexing multiple properties on a tag or an edge type (composite indexes), but do not support indexing across multiple tags or edge types.
Full-text Indexes
Full-text indexes are used to do prefix, wildcard, regexp, and fuzzy search on a string property. Features are as follows.
Full-text indexes allow indexing just one property.
Full-text indexes do not support logical operations such as
AND,OR, andNOT.